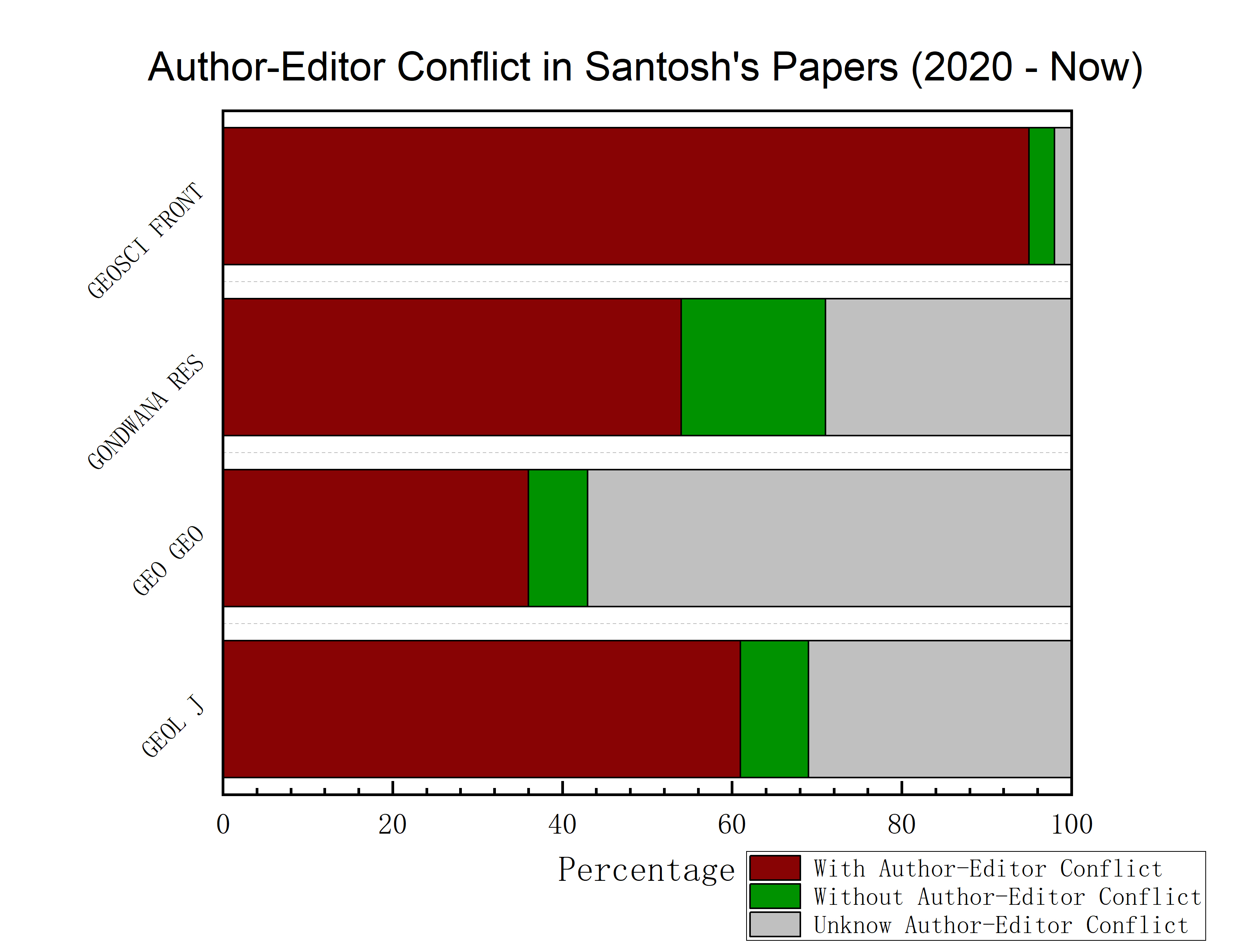
南方医科大学利用 ChatGPT 生成高仿实验图片,几乎能以假乱真
近日,南方医科大学为首的多国联合研究小组利用 ChatGPT 生成了高仿实验图片 [1]。作者团队表示,这些图片的逼真度甚至可以骗过经验丰富的专家,展示了“随手可得”的大语言模型在伪造实验图片的强大能力,而迫切需要学术社区的警觉。他们的结果发表在国际学术期刊《Journal of Hematology & Oncology》上。
无独有偶,2023 年,意大利的一个研究小组发表的一项报告 [2],旨在向我们展示大语言模型被利用于伪造实验数据的可能。他们利用 ChatGPT 生成了一组虚假的数据集,用以证明深板层角膜移植(deep anterior lamellar keratoplasty)比穿透性角膜移植(penetrating keratoplasty)能更好治疗圆锥角膜(keratoconus)患者。然而,作者在论文 [2] 中强调,这个结论从来没有获得任何的实验支持。

而南方医科大学最近的这项研究 [1] 进一步证明大语言模型甚至可以创造虚假的实验图片。他们利用 ChatGPT 生成了生成逼真的血液涂片图像(A),免疫荧光染色图像(B),H&E 染色图像(C),免疫组织学图像(D)以及和 Western Blot 图像(E)。这些图像的伪造效果可以与“生成对抗网络”(Generative Adversarial Networks,GAN)相媲美,足以欺骗经验丰富的专家。研究人员指出,由于大语言模型比 GAN 模型更容易获得,因而更可能被造假之人所利用。
随着大语言模型的快速发展,它为学术不端者提供了更为有力的工具,引起了日益增长的关注。虽然说,技术本无罪,对错都在于使用它的人。但是,面对着新的挑战,我们全球学术社区是否做好了应对的准备?
Reference